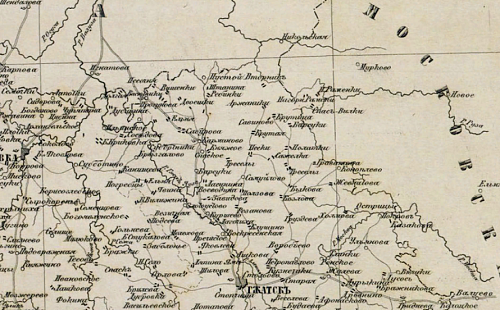
В современном мире рукописный текст занимает все более узкую нишу в системе накопления и распространения информации уступая свою роль «хранителя знания» цифровой среде и «символам на экране». Это вполне закономерно, ведь использование вычислительных средств позволяет кратно повысить возможности человека по работе с информацией. Вместе с тем, нерешенным остается вопрос о знании, уже накопленном в виде рукописей. Что с ним делать? Каков объем и значимость этого массива информации? Можно ли его использовать в информационной среде и, при этом, наравне с цифровыми данными? Все эти вопросы неизбежно отсылают нас к истории, как научному «арбитру» в спорах о ценности рукописного наследия.
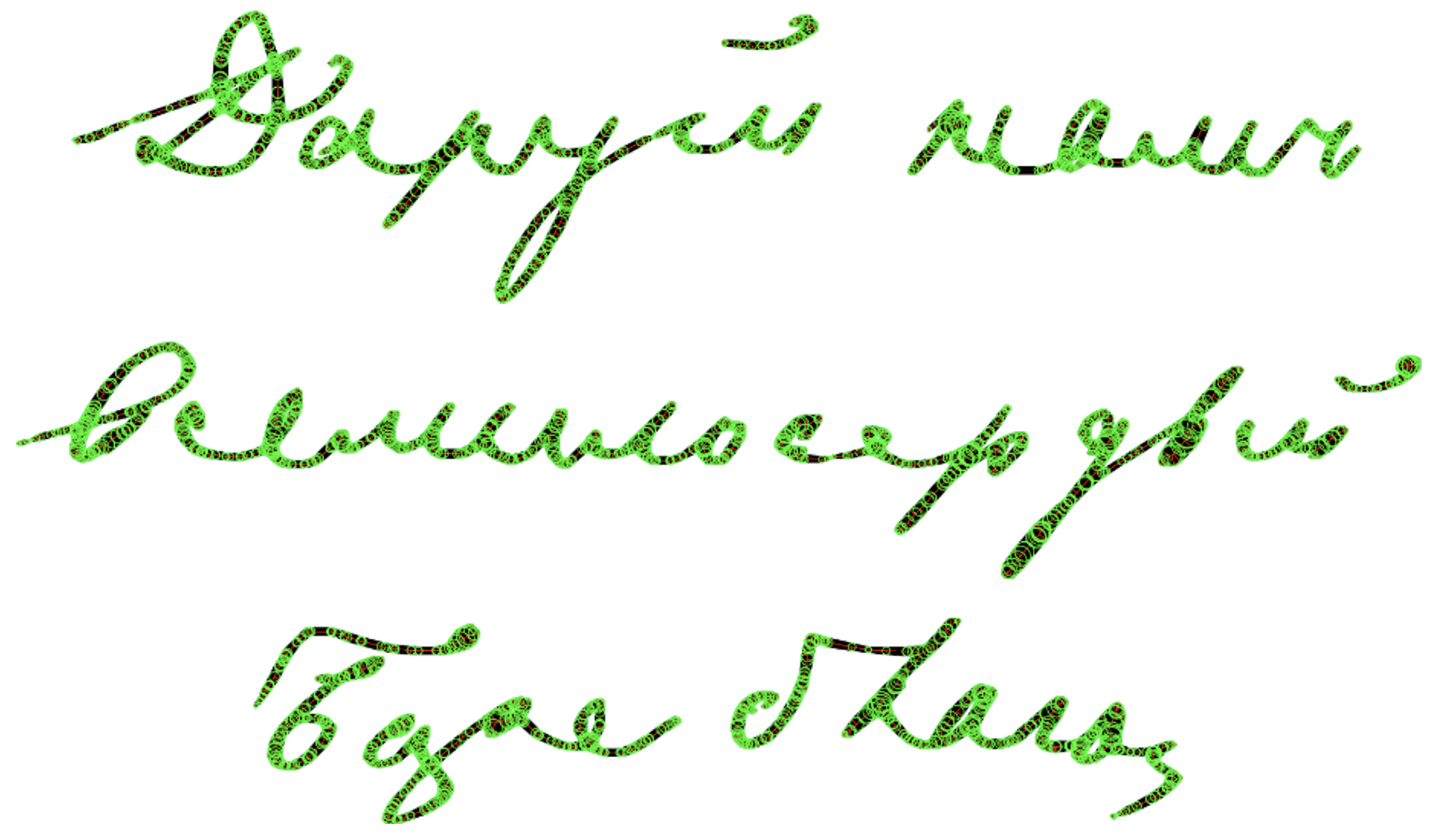
Скелеты бинарных изображений для следа пера адмирала Фёдора Петровича Литке. Скелеты изображены красным, вписанные круги – зелёным цветом (Источник: из архивов участников проекта).
В классическом представлении именно историк-исследователь знакомится с рукописями прошлого и преобразует найденную информацию с помощью научных публикаций, которые представляют историческое знание для широкой аудитории. Но открытым остается вопрос о методах работы исследователя с рукописями. До недавнего времени именно «ручная» расшифровка была единственным доступным инструментом, позволяющим понять структуру и смысл информации, содержащейся в рукописи. Однако развитие цифровых технологий, увеличение вычислительных мощностей и появление доступных инструментов работы с большими массивами данных (Big Data) позволили существенно расширить возможности по исследованию рукописей прошлого. Сейчас среди наиболее значимых в этом отношении технологий можно назвать оптическое распознавание символов (OСR), нейронные сети (в особенности графовые), а также алгоритмы интеллектуального анализа текста.

Автоматизированный поиск слов (выставление рамок для слов) на растровом изображении рукописи (Источник: из архивов участников проекта).
Современные возможности в применении цифровых технологий для решения гуманитарных задач по работе с историческими рукописями стали основой исследовательского проекта Института региональных исторических исследований ВШЭ под названием «Культурное наследие: интеллектуальный анализ и тематическое регулирование корпуса рукописных текстов» (проект поддержан Российским научным фондом; № 22-68-00066). В качестве основной цели проекта выступает формирование комплекса программных средств (сервисов), которые позволят не только эффективно распознавать (переводить на современный машиночитаемый текст) исторические рукописи конца XVIII – середины XX вв., но и проводить их автоматизированный интеллектуальный анализ: определять авторство, устанавливать атрибуты документа, идентифицировать тематику рукописей, выделять нарративы и внедрять поисковые механизмы внутри корпуса анализируемых рукописных документов.

Обложка личного дневника российского адмирала Федора Петровича Литке (Источник: ГАРФ. Ф. 1463. Оп. 1. Д. 1112. Обложка 2об.).
Решение такой амбициозной задачи началось с решения главной проблемы: поиска средств, позволяющих с высокой долей качества расшифровывать исторические рукописи. В качестве таких инструментов была выбрана технология оптического распознавания символов, базирующаяся на алгоритмах нейронных сетей. Параллельно определялись и сами исторические источники, вокруг которых были сформированы тестовые задания для обучения и тренировки нейросети. В качестве подобных источников выступили два корпуса рукописей XIX – начала XX вв.: перлюстрированные письма политических заключенных Смоленской каторжной тюрьмы (начало ХХ в., 67 листов с оборотами) [2] и частный дневник российского адмирала Федора Петровича Литке (первая половина XIX в., 1-4 тома, 1567 листов с оборотами) [3]. При работе с письмами каторжан исследовательская группа осуществила ручную расшифровку части писем, что позволило произвести обучение нейросетевой модели VerticalAttentionOCR (уровни строки и страницы). Ключевым показателем качества выступили такие показатели, как доля ошибок в символах (CER) и словах (WER).

Архивное дело с перлюстрированными письмами политических заключенных Смоленской каторжной тюрьмы (Источник: из архивов участников проекта).
В результате применения нейросети к распознаванию всего корпуса документов из архива Смоленской каторжной тюрьмы, удалось получить существенный результат: показатели качества, а именно доля ошибок в символах (CER) и словах (WER) для всей выборки оказалась ниже, чем у известной нейросетевой модели Russian Generic Handwriting 2 (Transkribus) [4]. Так, обученная модель VerticalAttentionOCR для строки показа результативность в 5% CER и 11% WER. Соотвественно для модели, ориентированной на распознавание всей страницы эти показатели составили 10% CER и 32% WER. Более сложная работа с разбивкой рукописи на строки дала более высокое качество распознавания. Подготовленная модель нейросети (уровня строки) в первой итерации смогла распознать 89 слов в рукописи из 100. Полученные результаты позволили в короткие сроки расшифровать 67 писем смоленских каторжан, найденных в фондах Государственного архива Смоленской области. Рукописный текст на 90% был автоматически расшифрован с помощью математических алгоритмов.
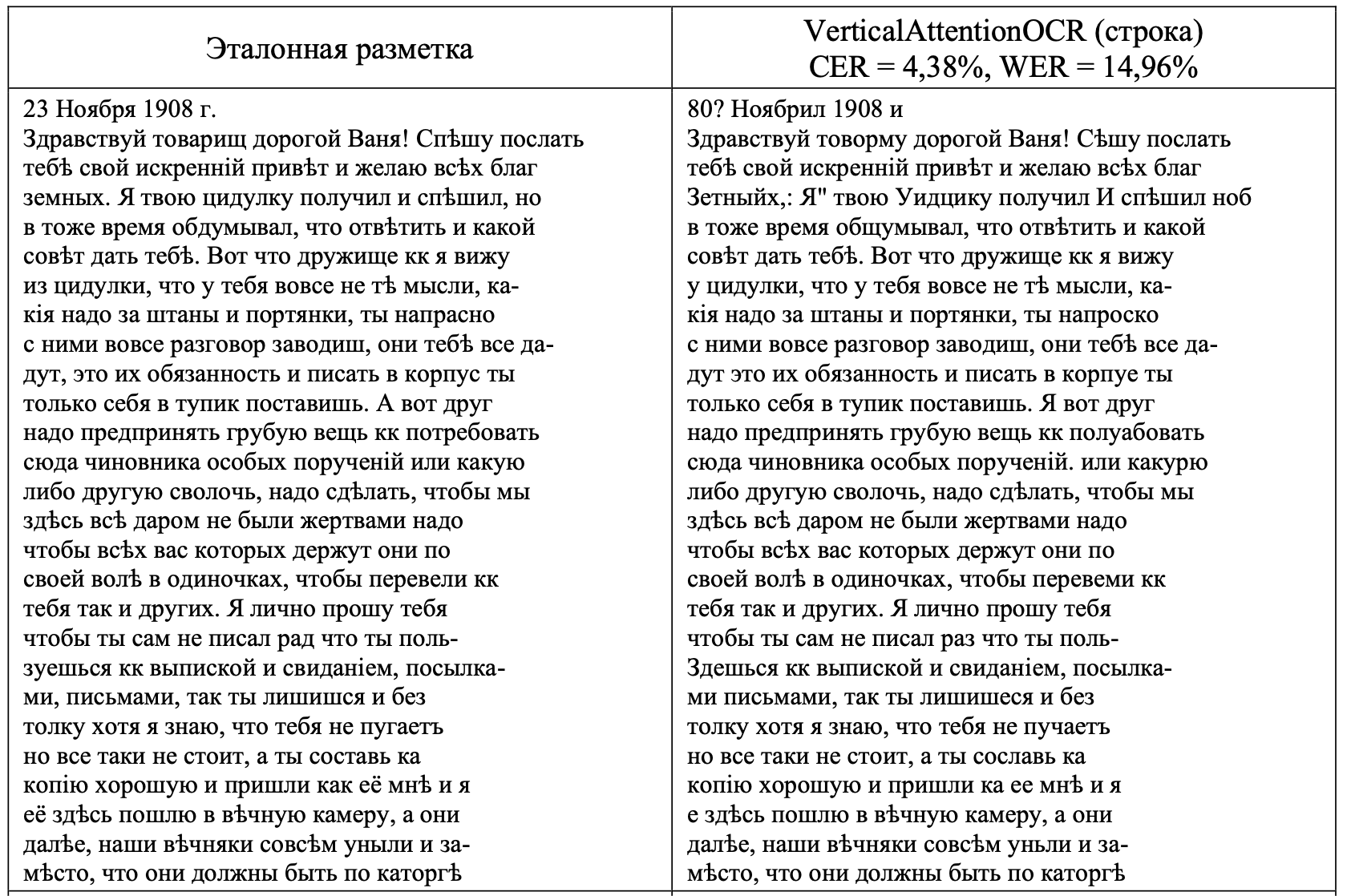
Результаты распознавания для модели VerticalAttentionOCR. Показатели качества приведены для отдельно взятой страницы (Источник: из личного архива участников проекта).
Совершенствование использования алгоритмов для расшифровки рукописного текста был продолжено при работе с дневником Федора Петровича Литке. Этот ценный исторический источник, содержащий в себе информацию о путешествиях адмирала, его службе при императорском дворе в качестве наставника младшего сына Николая I и о целом ряде событий, происходивших в столице империи в 1830-е гг. (например, смерти А. С. Пушкина в 1837 г.), пока не введен в научный оборот. Текст Литке был крайне сложен для системной расшифровки — непростая структура почерка сочетается в нем с обилием специальной терминологии и иностранных слов (морские термины, картографические понятия, вставки на нескольких иностранных языках и т.д.). Существенную сложность представляют также вертикальные заметки на полях листов. Использование при расшифровке дневника готовой нейросетевой модели и ее дообучение на новом материале позволили достичь высоких показателей распознавания: на некоторых листах дневника показатели CER были ниже 5%, а средние показатели WER для всего текста составили 10%. Нейронная сеть смогла верно распознать более 90 из 100 слов в рукописи Ф.П. Литке.

Построчная расшифровка дневника Ф.П. Литке (Источник: из личного архива участников проекта).
Полученные результаты позволяют сделать вывод о существовании в настоящий момент реальной перспективы для создания инструментов, предоставляющих возможность осуществить 90% объема работы по расшифровке текстов исторических рукописей за счет математических алгоритмов (нейронных сетей). Ожидается, что в процессе работы над проектом «Культурное наследие: интеллектуальный анализ и тематическое регулирование корпуса рукописных текстов» показатели качества будут еще выше и составят около 98 % для CER и 95 % для WER: нейронные сети будут успешно распознавать 98 слов из 100 для абсолютного большинства исторических рукописей. Такой подход поможет сэкономить значительный объем времени, затрачиваемый исследователем на разбор рукописного текста. Успешное распознавание выступает, однако, не единственным условием эффективного внедрения подобной технологии. Качественный разбор исторической рукописи должен сопровождаться проведением первоначального интеллектуального анализа – определение тематики источника, идентификация ключевых слов, исследование базовой семантики. Эти задачи, традиционно выполняемые человеком/экспертом, могут быть реализованы с привлечением математического алгоритма.

Этапы работы с рукописным текстом (Источник: из личного архива участников проекта).
В рамках проекта «Культурное наследие» исследовательский коллектив протестировал использование технических возможностей для оценки комплекса писем смоленских каторжан. Работа была выстроена поэтапно: 1) были определены наиболее часто встречающиеся слова (ключевые слова); 2) выборка слов была сведена в несколько тематических словарей; 3) с помощью статистического анализа частотности ключевых слов было определено, какие темы (или нарративы) доминируют в том или ином письме каторжанина; 4) на финальном этапе работы были идентифицированы варианты последовательности нарративов («ведущий» - «ведомый»). В целом, алгоритм дал возможность определить тематику как отдельного письма, так и всего комплекса писем в целом [5].

Визуальное выделение цветом мест на растровом изображении, содержащих ключевые слова (Источник: из личного архива участников проекта).
С помощью визуального редактора ключевые слова были графически выделены и маркированы цветом в зависимости от темы (нарратива). Использование такого метода в дальнейшем позволит специалистам быстро обнаружить необходимую информацию на конкретной странице. Благодаря распознаванию практически всего текста, появилась и функциональная возможность навигации внутри комплекса писем: исследователь может найти в тексте перечень интересующих его слов и выражений и сразу перейти к конкретному листу документа, где будет графически выделен его поисковой запрос.

Выделение ключевых слов в тексте письма. Цветовое маркирование указывает на принадлежность ключевого слова к конкретному нарративу (Источник: из личного архива участников проекта).
Благодаря изысканиям по проекту «Культурное наследие: интеллектуальный анализ и тематическое регулирование корпуса рукописных текстов» исследовательский коллектив смог на практике ответить на несколько вопросов, заданных в начале статьи. В настоящий момент огромный объем рукописей, накопленных в архивохранилищах и представляющих интерес, прежде всего, для историков и филологов, может быть интегрирован в информационную среду. В настоящий момент разрабатываются механизмы, позволяющие с высокой долей качества распознавать рукописный текст (в том числе XVIII – начала ХХ вв.) и осуществлять навигацию внутри рукописи с целью понимания его содержания (без предварительного полного прочтения).

Визуализация перехода от цветного изображения к непрерывному скелету (Источник: из личного архива участников проекта).
Сейчас коллектив проекта работает над реализацией новой концепции графовой нейроннной сети, которая будет анализировать исторические источники не как с растровые изображения (картинки или сканы страниц), а так набор «скелетов», полученных с помощью методов обработки следа пера автора. В будущем это позволит создать универсальный алгоритм автоматического распознавания рукописи, работа которого не будет изначально осложнена необходимостью интерпретации особенностей почерка конкретного автора или специфики языковых форм. Использование графов также позволит в автоматическом режиме определять слова на иностранном языке и распознавать их по заранее настроенным алгоритмам.
Антон Лаптев
кандидат исторических наук
научный сотрудник Института региональных исторических исследований,
НИУ Высшая школа экономики
[1] - Исследование проведено в рамках проекта Российского научного фонда № 22-68-00066 «Культурное наследие России: интеллектуальный анализ и тематическое моделирование корпуса рукописных текстов».
[2]- Государственный архив Смоленской области (ГАСО). Ф. 404. Оп. 1. Д. 631.
[3]- Государственный архив Российской Федерации (ГАРФ). Ф. 1463. Оп. 1. Д. 1111-1114.
[4]- AI-powered platform for text recognition, transcription and searching of historical documents – from any place, any time, and in any language. URL: https://readcoop.eu/transkribus/?sc=Transkribus.
[5] Болтунова Е. М., Лапетв А.К., Ломов Н. А. Каторга и рождение новой политической риторики: анализ корпуса писем политических заключенных начала XX в. // Имагология и компаративистика. 2023. № 20. С. 297-318.
Похожие материалы